前回、CSVファイルの1列の重複値の削除を紹介しました。
今回は2列のデータを使い、1列の中に重複値があればその行ごと削除するの方法を紹介します。
重複値の削除
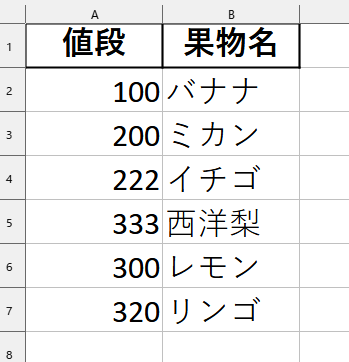
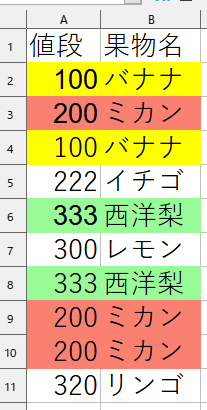
CSVファイルの値段という列に重複している値が複数あります。重複している値段があれば、果物の列も削除する、つまり行ごと削除するプログラムを作成します。
必要なライブラリ
必要なライブラリは pandas と openpyxl になります。
インストールされていなければ、下記のコマンドを実行して下さい。
pip install pandas
pip install openpyxlサンプルコード
import pandas as pd
file1 = "C:/Labo/duplicate.csv"
file2 = "C:/Labo/unique.xlsx"
df = pd.read_csv(file1, encoding='shift-jis')
df.drop_duplicates(subset=['値段'], keep='first', inplace=True)
df.to_excel(file2, index=False)
ライブラリのインポートは pandas のみになりますが、エクセルファイルで保存するので、openpyxl も必要になります。
file1 が重複値が入っているCSVファイル、 file2 が重複値を取り除いたファイルになります。
次が重複した行を削除する関数になります。
df.drop_duplicates(subset=['値段'], keep='first', inplace=True)keep = ‘first’ は上から行を見て重複しているものの最初を残すというオプションになります。最後は ‘last’、すべて削除する場合は ‘false’ を keep に代入にします。
inplace=True はオリジナルのデータフレームを変更します。False であれば新しいベータフレームを作る場合に使います。
new_df = df.drop_duplicates(subset=['値段'], keep='first', inplace=False)実行すると重複セルを削除したファイルが出来上がります。