
みなさん、こんにちは。
今回はデータファイルの結合方法を紹介しようと思います。
データファイルの結合?
今回のデータファイルというのはCSVファイルです。
統計や実験などで使用される装置では、ログデータをCSVファイル形式で出することが出来ます。
ただ、毎日、ログを出力して、更新分だけを手作業で入力するということが多いのではないでしょうか。
例えば、数日分のログを取り忘れて、後から追記するのは、ミスも発生します。そうであれば、PYTHONでプログラムを組んで、まとめた方が楽だと思い、今回のプログラムを思いつきました。
プログラムの内容
今回使用するデータは為替データです。
ファイル1には2月25日から3月4日までの情報、ファイル2には3月1日から3月11日までの情報になっています。

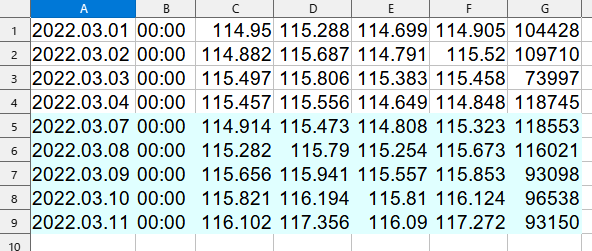
今回は、データ1にデータ2のデータ1の持っていない情報(3月7日から3月11日)を追記するプログラムを作ります。
プログラムコード
import pandas as pd
file_a = "C:/Labo/file01.csv"
file_b = "C:/Labo/file02.csv"
df1 = pd.read_csv(file_a, header=None)
df2 = pd.read_csv(file_b, header=None)
df3 = pd.concat([df1, df2])
df3.drop_duplicates(subset=None, keep="first", inplace=True)
df3.to_csv(file_a, mode='w', index=False, header=None)
1行目 ライブラリをインポート
今回使用するのは pandas です。pandasのライブラリが無い場合は、下記のコマンドを実行してインストールしてください。
pip install pandas3,4行目 データファイルの定義
file_aはまとめる側のファイル、file_bは更新分が含まれるファイルになります。
6~8行目 データの読み込み、データフレームの結合
それぞれのデータを読み込み、データフレーム df1 、 df2 に格納します。
concatを使い、2つのデータフレームをデータフレーム df3 にまとめます。
ここで重要なのは pd.concat([df2, df1])という並びにせずに、pd.concat([df1, df2])と新しいのデータフレームを後に記述して下さい。
df3 = pd.concat([df1, df2])当然のことながら、df3の中は下記の通りになります。データフレームをまとめただけなので、重複分が発生します。この重複分を削除すれば、データは完成です。では次に進みましょう。
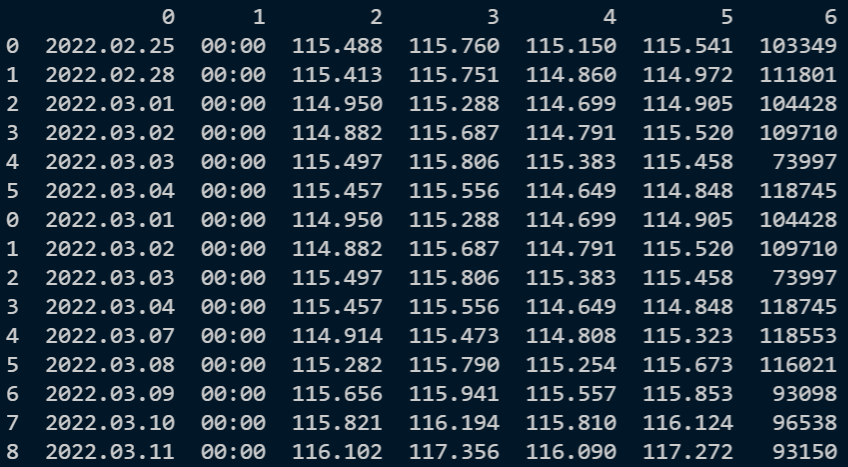
10行目 重複分を削除
drop_duplicates はデータフレーム内に重複するデータがあれば、重複分を削除します。
df3.drop_duplicates(subset=None, keep="first", inplace=True)subset=Noneの場合、特定の列の要素の重複分を判定します。今回は、行全体の重複を判定するので、Noneとします。
keep=”first”の場合、例えば2つ重複するデータがあるとすると、最初のデータは保存されます。
inplace=Trueの場合、重複したデータが削除されます。
keep=”first”、inplace=True とすることで、データが重複している場合、古いデータが残ることになります。
8行目 ファイルに書き込む
df3.to_csv(file_a, mode='w', index=False, header=None)出来上がったデータフレームをファイルに書き込みます。
mode=’w’ から分かるように、追記ではなく、新規書き込みになっています。
追記の方が処理が速いのではと思われるかもしれませんが、上記のコードで、2000行のデータの処理は1,2秒で処理されので、それほど差異はないと感じています。なにより、コードが簡単なのがいいですよね。
プログラムを実行すると下記のように新しいデータだけ追記された形になっています(色は分かりやすいためにつけています)。

まとめ
いかだったでしょうか。
ログ情報をまとめる際には、是非、上記のプログラムを使ってみて下さいね。
「役に立った!」と思れましたら、下のSNSボタンで記事のシェアをしていただけると嬉しいです!

コメント