
みなさん、こんにちは。
今回はSklearnで簡単な線形回帰を紹介しようと思います。
初めてSklearnを使う方にはわかりやすい内容となっています。
Sklearnと線形回帰
Sklearnは機械学習のライブラリとして有名です。
既存のデータとSklearnを使えば、将来に起こる事象を予想することが出来ます。
そして、Sklearnの機能の中で、線形回帰があります。
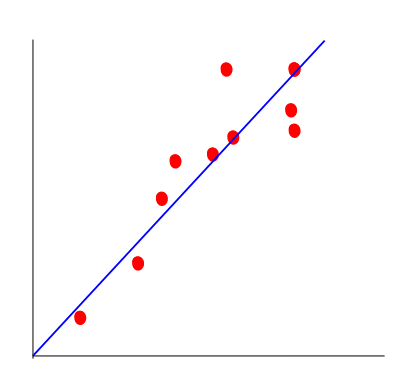
線形回帰というのは、下のグラフように複数のデータから最適な線形を求めます。青い線を求めることで、あるXの最適なYを求めることが出来ます。
プログラムの内容

今回は上記のデータを使って、X=5の時のYの値はどのようになるかを求めます。Y=2Xという方程式の関係なので、データからは完全な再帰回帰が求められるので、Yの値は10になるはずです。
ライブラリのインストール
今回は、SklearnとNumpyのライブラリを使用します。インストールされていなければ、下記のコマンドを実施してインストールをして下さい。
pip install sklearn
pip install numpyプログラムコード
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1], [2], [3], [4]])
Y= np.array([[2], [4], [6], [8]])
reg = LinearRegression().fit(X, Y)
print(reg.predict(np.array([[5]])))
print(reg.coef_)
print(reg.intercept_)1、2行目 ライブラリをインポート
LinearRegressionは線形回帰の関数になります。
5,6行目 データの設定
XとYのデータはnp.array型で設定します。ここが重要です。
Sklearnのデータを扱う時はnumpy配列を使用するということを忘れないでください。
9行目 データを再帰回帰処理する
reg = LinearRegression().fit(X, Y)XとYのデータを再帰回帰処理します。
regという中に再帰回帰する計算式が収まるという形になります。
11行目 X=5の時の予想
print(reg.predict(np.array([[5]])))最後にX=5の時の予想を出力します。この場合、np.array([])というデータ型で入力して下さい。
predictは英語で予想するを意味します。
プログラムを実行すると、下記のように10が出力されます。
[[10.]]13,14行目 傾きと切片
print(reg.coef_)
print(reg.intercept_)reg.coef_は傾き、reg.intercept_は切片になります。
[[2.]]
[0.]出力結果は上記になりますので、Y=2X+0という式になります。
まとめ
いかだったでしょうか。
今回はSklearnの簡単な使い方を紹介しました。
まずは簡単な処理を覚えて、より深いSklearnの処理に使い方について覚えていければいいですね。
「役に立った!」と思れましたら、下のSNSボタンで記事のシェアをしていただけると嬉しいです!

コメント