

今回はLibreOfficeの表計算ソフト『Calc』の表を操作するプログラムを作成したいと思います。
LibreOffice CalcはMicrosoftのExcelに相当するソフトです。Excelを購入出来ない人にとってはLibreOfficeは必須ですよね。
では、今回、作成するプログラムは下記になります。
今回は、LibreOfficeの表計算『Calc』のファイルの操作と共に、表計算の操作の基本を覚えましょうね。
ライブラリ『pandas』, 『numpy』, 『odfpy』をインストール
まず、表計算を操作するためのライブラリ『pandas』, 『numpy』をインストールします。『odfpy』はCalcを操作するライブラリになります。
pip install numpy pip install pandas pip install odfpy
データを準備する
フォルダ「C:\Labo\python\librecal01」に、「score.ods」という名前のファイルを作成し、下記の表を作ります。
同じファイル内にシート「Sheet1」、「Sheet2」を、それぞれ作って下さい。
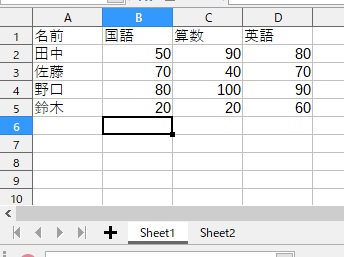
『Sheet1』の表

『Sheet2』の表
odsファイルを読み込んで表示させる
import pandas as pd import numpy as np odsfile = "C:/Labo/python/librecal01/score.ods" df =pd.read_excel(odsfile, engine="odf") print(df)
1、2行目:『pandas』と『numpy』のライブラリをインポートします。ここで、『odfpy』をインポートしていません。『pandas』内に『odfpy』が含まれるので、インポートする必要はありません。
4行目:ファイルを絶対パスで指定します。
6行目:重要なポイントです。エクセルファイルを読み込むときは必要ありませんが、odsファイルを読み込むときは、オプションで『engine=”odf”』を追記する必要があります。
そして、『df』はデータフレームの略です。『df』を出力すると、下記の通りになります。
名前 国語 算数 英語 0 田中 50 90 80 1 佐藤 70 40 70 2 野口 80 100 90 3 鈴木 20 20 60
ここでは『Sheet1』のみが表示されています。つまり、6行目のコード内でシートを指定しない時は、並びで一番初めのシートが読み込まれることになります。
シートを指定して読み込む
シートを別々に読み込むためには、『pd.read_excel』のオプションで下記のようにシートを指定します。
df1 =pd.read_excel(odsfile, engine="odf", sheet_name="Sheet1") df2 =pd.read_excel(odsfile, engine="odf", sheet_name="Sheet2") print(df1) print(df2)
出力結果は下記の通りです。これで『Sheet1』、『Sheet2』が無事に読み込むことができました。
名前 国語 算数 英語 0 田中 50 90 80 1 佐藤 70 40 70 2 野口 80 100 90 3 鈴木 20 20 60 名前 社会 理科 体育 0 田中 30 50 100 1 佐藤 80 70 50 2 野口 95 80 30 3 鈴木 50 60 70
シートが複数ある場合、最初のシートも、上記のように、指定して読み込むことをおススメします。そうすれば、万が一、シートの順番が変更してしまった場合も、シートを間違えることなく、読み込むことが出来ます。
データフレームとは?
先ほどのデータフレームを出力すると、odsファイルの表の通りに出力されました。
リスト等を定義して、データを1行ずつ読み込んでいくことと異なり、非常に簡単です。ライブラリ『pandas』を使う理由が分かりましたね。
平均値を求める
教科の平均を求める
各教科の平均はライブラリ『numpy』を使うと一発で求める事が出来ます。
print(np.mean(df1)) print(np.mean(df2))
『np.mean(df)』は平均値を求める『numpy』の関数です。
出力結果は下記になります。平均値が求められていますね。
dtype: float64というのは出力された結果の型になります。
国語 55.0 算数 62.5 英語 75.0 dtype: float64 社会 63.75 理科 65.00 体育 62.50 dtype: float64
個人の平均を求める
では、各個人の平均を出力しましょう。
先ほどの教科は列ごとの平均になりましたが、次は、行ごとの平均になります。行の平均を求める時は、『axis=1』とオプションを加えます。
print(np.mean(df1, axis=1)) print(np.mean(df2, axis=1))
出力結果は下記の通りになります。各個人の平均が求められていますね。
0 73.333333 1 60.000000 2 90.000000 3 33.333333 dtype: float64 0 60.000000 1 66.666667 2 68.333333 3 60.000000 dtype: float64
おわりに
いかがだったでしょうか。
LibreOfficeでも、エクセルでも、データフレーム化さえすれば、扱いは同じです。
次回は各個人の平均がシート毎に別れていたので、『Sheet1』と『Sheet2』をまとめて平均をとるプログラムに拡張したいと思います。
![スッキリわかるPython入門 第2版 (スッキリわかる入門シリーズ) [ 国本 大悟 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/6366/9784295016366_1_4.jpg?_ex=128x128)
コメント