

みなさん、こんにちは。
今回はOCR(文字認識)のソフトTesseractで日本語を認識するプログラムを作成してみようと思います。
今回は、準備が大半で、プログラムはほんのわずかです^^;。
OCR(文字認識)とは?
まず、OCR(文字認識)の説明をします。
OCRは、Optical Character Recognitionの略で、光学的文字認識と訳されます。
一般的に知られるようになったのは、プリンターにスキャナーの機能が追加されてでしょうか。スキャンされた画像から文字を認識するOCR機能が流行り始めました。
パソコン上の画像から文字認識することは、Optical=光学ではありませんが、一般的に、「OCR=文字認識」という認識になっています。
準備すること
PYTHONでは追加ライブラリをインストールすれば、それで済みましたが、今回は違います。
❶ 文字認識ソフトTesseractをパソコンにインストール
➋ Tessaractの日本語データをインストール
❸ Pythonのpytesseractのライブラリをインストール
文字認識ソフト「Tesseract」をWindowsパソコンにインストール
では、最初に文字認識ソフト「Tesseract」をWindowsパソコンにインストールする方法を説明します。
下記のサイトにアクセスします。
ページを下にスクロールすると、ソフトのインストーラーファイルのリンク部分が表示されます(下の画像を参照)。2022年5月時点の最新バージョンは5.1になりますので、後日、バージョンが変更しているかもしれませんのでご了承ください。
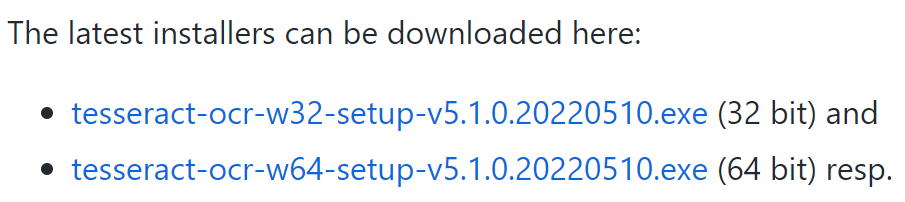
パソコンにインストールされているOSが32ビットか64ビットかでインストールソフトが変わるので、使用するパソコンのビット数に合うものを選択して下さい。
ファイルをダウンロードしたら、ダブルクリックをして、インストールを行ってください。インストールする際は、インストール先フォルダの確認をして下さい。通常であれば、下記のフォルダにインストールされます。次の作業の、日本語のデータをインストールする際に必要になります。
C:\Program Files\Tesseract-OCRこれで、Tesseractのインストールは完了です。
日本語データのインストール
次に日本語のデータをインストールします。標準では英語のデータのみがインストールされています。
日本語のデータを取得する為に、下記のサイトに行きます。
下にスクロールすると、日本語のデータのリンクが2つ表示されています。この2つをダウンロードします。

日本語のデータ
ダウンロードしたファイルは、先ほどインストールしたTesseract-OCRのフォルダの中にある「tessdata」というフォルダに入れて下さい。
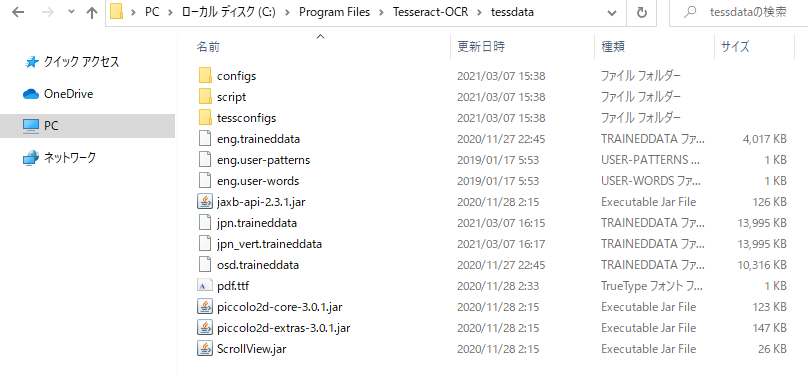
これで日本語データのインストールは完了です。
PYTHON用ライブライ「pytesseract」をインストール
最後に、PYTHON用のライブラリ「pytesseract」をインストールします。
下記のコマンドを実行して下さい。
pip install pytesseractこれで文字認識するプログラムを作成する準備が整いました。
文字認識するプログラム
プログラム解説
import pytesseract
from PIL import Image
text = pytesseract.image_to_string(Image.open('C:/Labo/image/test1.jpg'),lang='jpn')
print(text)1、2行目 ライブラリのインポート
今回は「pytesseract」の他に、画像用ライブラリ「PIL」を使用します。これは、画像から文字を認識する為、画像を開くライブラリが必要になってくるからです。
5行目 画像から文字へ
画像から文字にする為に、pytesseract.image_to_stringという関数を使います。
langには、先ほどインストールした日本語のデータを指定します。日本語の横書きであれば「jpn」、縦書きであれば「jpn_vert」を選択します。
出力結果
下の2つの画像で試してみました。
横書き
縦書き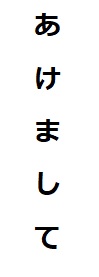
| lang | 横画像 | 縦画像 |
|---|---|---|
| jpn | あけ まし て | あ 地 し て |
| jpn_vert | _いテムesa | あ け ま し て |
上記の出力結果のように、画像上の文字が縦書きか横書きかで、適したlangを選択しないと、正しく出力されないことがわかりました。
ただ、langを適切に選んでいる場合は、100%正しい出力結果が得られていることが分かります。すごいですね。
日本語以外のデータ
数字や英語を使用する場合は、langの部分を削除するか、lang=engと置き換えて下さい。
text = pytesseract.image_to_string(Image.open('C:/Labo/image/test1.jpg'))また、他の言語を扱う時は、日本語のデータをインストールした時と同じように、その言語のデータファイルをインストールして下さい。その場合はlangにはそのファイル名を指定すればいいだけです。
まとめ
いかがだったでしょうか。
文字認識って面白いですよね。今回は試しませんでしたが、漢字も認識しますよ。
是非、色々と試していてください。
「役に立った!」と思れましたら、下のSNSボタンで記事のシェアをしていただけると嬉しいです!
![スッキリわかるPython入門 第2版 (スッキリわかる入門シリーズ) [ 国本 大悟 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/6366/9784295016366_1_4.jpg?_ex=128x128)
コメント